CDK Pipelines(Python)を使ってマルチアカウントへデプロイできるパイプラインを作成する
0. パイプラインをつくって試行回数を増やしたい
さて、マルチアカウントでSSOを設定する方法について前回の記事でまとめました。
今度はマルチアカウントにデプロイするパイプラインを作りたいと思います。
数パターンを考えましたが、
- devアカウント、stgアカウント、prodアカウントそれぞれにパイプラインを作成する
- manageアカウントにパイプラインを作成して各アカウントへクロスアカウントデプロイ
stgにデプロイして、確認してからApprovalするというパターンを取りたかったので、以下の構成を目指しました。

マネコンぽちぽちで試しにつくっていましたが、CodePipelineのDeployステージのCloudFormationで苦戦して断念。
そこでこちらのAWS公式ブログ を参考にCDK pipelinesを試しました。
ブログはTypescriptですが今回はpythonで試してみます。
サンプルのプロジェクトはこちらにて公開しています。
以下の手順で進めていきます
- 0. パイプラインをつくって試行回数を増やしたい
- 1. account idを調べる
- 2. secrets managerにgithub-tokenを登録する
- 3. cdk init
- 4. remote repositoryとしてgithubを登録する
- 5. .envの設定等
- 6. クロスアカウントの信頼関係を登録
- 7. lambdaのstackの追加
- 8. pipelineのstackを追加
- 9. app.pyを修正
- 10. pipelineのstackをcdk deploy
- 11. githubにpush
- まとめ
1. account idを調べる
マネコンからならこちらを確認。

2. secrets managerにgithub-tokenを登録する
AWSのmanageアカウントのSecretManagerにtokenを登録

3. cdk init
ひとまず今回はHelloAppという名前のプロジェクトということで作成します。
$ mkdir HelloApp && cd HelloApp/ $ cdk init --language=python $ source .venv/bin/activate $ pip install -r requirements.txt
4. remote repositoryとしてgithubを登録する
$ git remote add origin <git-hubのhttps url>
5. .envの設定等
今回の例では影響が少ないですが、アカウントIDやバケット名などの情報は環境変数で管理していきます。
$ pip install python-dotenv $ touch .env $ echo 'DEV_ACCOUNT_ID="<AWSアカウントID>"' >> .env $ echo 'STG_ACCOUNT_ID="<AWSアカウントID>"' >> .env $ echo 'PROD_ACCOUNT_ID="<AWSアカウントID>"' >> .env $ echo 'MANAGE_ACCOUNT_ID="<AWSアカウントID>"' >> .env
また、cdk独自の設定項目も追加
{ "app": "python3 app.py", "context": { "@aws-cdk/core:newStyleStackSynthesis": "true" <= これを追加 } }
また、今回使用するcdkのモジュール類をpip installする setup.pyのsetuptools.setup()のinstall_requiresに以下を追加。 バージョンは適宜修正してください。
[
"aws-cdk.core==1.88.0",
"aws-cdk.aws-codepipeline==1.88.0",
"aws-cdk.aws-codepipeline-actions==1.88.0",
"aws-cdk.aws-codecommit==1.88.0",
"aws-cdk.aws-codebuild==1.88.0",
"aws-cdk.pipelines==1.88.0",
"aws_cdk.aws_lambda==1.88.0",
"aws-cdk.aws_logs==1.88.0"
]
$ pip install -r requirements.txt
6. クロスアカウントの信頼関係を登録
クロスアカウントでCloudFormationデプロイをする際に、このコマンドで信頼関係を定義することができる
$ cdk bootstrap --profile <manageアカウントのprofile> --cloudformation-execution-policies arn:aws:iam::aws:policy/AdministratorAccess aws://<manageアカウントのID>/ap-northeast-1 $ cdk bootstrap --profile <devアカウントのprofile> --trust <manageアカウントのID> --cloudformation-execution-policies arn:aws:iam::aws:policy/AdministratorAccess aws://<devアカウントのID>/ap-northeast-1 $ cdk bootstrap --profile <stgアカウントのprofile> --trust <manageアカウントのID> --cloudformation-execution-policies arn:aws:iam::aws:policy/AdministratorAccess aws://<stgアカウントのID>/ap-northeast-1 $ cdk bootstrap --profile <prodアカウントのprofile> --trust <manageアカウントのID> --cloudformation-execution-policies arn:aws:iam::aws:policy/AdministratorAccess aws://<prodアカウントのID>/ap-northeast-1
7. lambdaのstackの追加
今回は簡単なLambdaをサンプルでデプロイします。
mkdir -p functions/hello touch functions/hello/index.py
lambda自体は簡単なreturnをするだけ
# functions/hello/index.py def lambda_handler(event, context): return { "statusCode": 200, "body": "hello from lambda" }
そして、これらのコードをデプロイするためのCDKを記載します。
$ touch hello_app/hello_app_stack.py
# hello_app/hello_app_stack.py from aws_cdk import ( core, aws_lambda as lambda_, aws_logs as logs, ) class HelloAppStack(core.Stack): def __init__(self, scope: core.Construct, construct_id: str, **kwargs) -> None: super().__init__(scope, construct_id, **kwargs) hello_app_func = lambda_.Function(self, "HelloAppFunction", code=lambda_.Code.from_asset('functions/hello'), handler="index.lambda_handler", runtime=lambda_.Runtime.PYTHON_3_8, tracing=lambda_.Tracing.ACTIVE, timeout=core.Duration.seconds(29), memory_size=128, ) logs.LogGroup(self, 'HelloAppFunctionLogGroup', log_group_name='/aws/lambda/' + hello_app_func.function_name, retention=logs.RetentionDays.TWO_WEEKS )
8. pipelineのstackを追加
(1)PipelineStageのStackでlambdaのStackを読み込み
PipelineStageクラスの中で7.で作成したLambdaStackのクラスを初期化します。
# pipeline_lib/pipeline_stage.py from aws_cdk import ( core ) from hello_app.hello_app_stack import HelloAppStack class PipelineStage(core.Stage): def __init__(self, scope: core.Construct, id: str, **kwargs) -> None: super().__init__(scope, id, **kwargs) HelloAppStack(self, self.node.try_get_context('service_name') + '-stack')
つづいて、必要に応じでステージに応じたpipelineのスタックを追加します。 Approvalつきのprodのpipelineをいかに例示します。
# pipeline_lib/pipeline_master_stack.py from aws_cdk import ( aws_codepipeline as codepipeline, aws_codepipeline_actions as actions, aws_codecommit as codecommit, aws_codebuild as codebuild, pipelines, core ) from pipeline_lib.pipeline_stage import PipelineStage import os STAGE = "stg" STAGE2 = "prod" class PipelineMasterStack(core.Stack): def __init__(self, scope: core.Construct, id: str, **kwargs) -> None: super().__init__(scope, id, **kwargs) sourceArtifact = codepipeline.Artifact() cloudAssemblyArtifact = codepipeline.Artifact() pipeline = pipelines.CdkPipeline(self, 'Pipeline', pipeline_name=self.node.try_get_context( 'repository_name') + "-{}-pipeline".format(STAGE), cloud_assembly_artifact=cloudAssemblyArtifact, source_action=actions.GitHubSourceAction( action_name='GitHub', output=sourceArtifact, oauth_token=core.SecretValue.secrets_manager('github-token'), owner=self.node.try_get_context( 'owner'), repo=self.node.try_get_context( 'repository_name'), branch=STAGE2 ), synth_action=pipelines.SimpleSynthAction( synth_command="cdk synth", install_commands=[ "pip install --upgrade pip", "npm i -g aws-cdk", "pip install -r requirements.txt" ], source_artifact=sourceArtifact, cloud_assembly_artifact=cloudAssemblyArtifact, environment={ 'privileged': True }, environment_variables={ 'DEV_ACCOUNT_ID': codebuild.BuildEnvironmentVariable(value=os.environ['DEV_ACCOUNT_ID']), 'STG_ACCOUNT_ID': codebuild.BuildEnvironmentVariable(value=os.environ['STG_ACCOUNT_ID']), 'PROD_ACCOUNT_ID': codebuild.BuildEnvironmentVariable(value=os.environ['PROD_ACCOUNT_ID']), 'MANAGE_ACCOUNT_ID': codebuild.BuildEnvironmentVariable(value=os.environ['MANAGE_ACCOUNT_ID']) } ) ) stg = PipelineStage(self, self.node.try_get_context('repository_name') + "-{}".format(STAGE), env={ 'region': "ap-northeast-1", 'account': os.environ['STG_ACCOUNT_ID']} ) stg_stage = pipeline.add_application_stage(stg) stg_stage.add_actions(actions.ManualApprovalAction( action_name="Approval", run_order=stg_stage.next_sequential_run_order() )) prod = PipelineStage(self, self.node.try_get_context('repository_name') + "-{}".format(STAGE2), env={ 'region': "ap-northeast-1", 'account': os.environ['PROD_ACCOUNT_ID']} ) pipeline.add_application_stage(app_stage=prod)
一連の処理の中でcdkのcontextから値をとっている部分があるので、 sampleを動かすためには以下の設定も必要
$ touch cdk.context.json
{ "owner": "<github repositoryの組織>", "repository_name": "<repository名>", "service_name": "hello-app" }
9. app.pyを修正
cdkのエントリーポイントを修正して、pipelinesのstackを構成するように指定する
# app.py from aws_cdk import core from pipeline_lib.pipeline_master_stack import PipelineMasterStack from dotenv import load_dotenv import os load_dotenv() app = core.App() PipelineMasterStack( app, "{}-master-pipeline".format(app.node.try_get_context('service_name')), env={ 'region': "ap-northeast-1", 'account': app.account } ) app.synth()
10. pipelineのstackをcdk deploy
ここまでてきていればいいので
$ cdk list --profile <manageアカウントのprofile>
でデプロイ可能なapp名を確認して、
$ cdk deploy --profile <maageアカウントのprofile> <デプロイするapp名>
11. githubにpush
プロジェクト全体をgithubにpushしてpipelineが動作するのを確認する。
まとめ
cdk pipelinesを使用してかなり簡単にパイプラインを作成することができました。 これを参考に雛形のプロジェクトをつくっておけばマイクロサービス * ステージごとなど、たくさんのパイプラインも手間なく作れますね。
以上です。
複数アカウントの管理を簡略化するためAWS SSOを使用する
1. 最初に
個人の学習目的のためにWebアプリケーションを作成することを決意した。 せっかくなのでマルチアカウントでの運用を試してみたいと思う。
目指すのは以下のかたちです。
- 黒い四角形はアカウント名
- 緑色の枠はOU

- Adminアカウント
- Manageアカウント
- Appsアカウント
- ひとまずはDevとProdでランドスケープを分けたい
- ステージングは追々作るようなら作る
マルチアカウント戦略を進めることになるが、アカウント切り替えの度にログインしていたのでは 大変煩雑なのでシングルサインオンを実践したいと思う。
実務ではOneLoginを使用しているが、
- 今回はAWSアカウントの切り替えが手軽にできればよい(他アプリ等は不要)
- 個人開発なのでADとかない(SSOは最近ユーザープールを内部でもてるようになった) と言う点からAWS SSOを採用することにする。
以下は具体的な手順。 開発の初期段階でこだわりすぎると大変なのでマネジメントコンソールでぽちぽち作成した。
2. Organizationsにアカウントを登録する
(1) まずはアカウントの作成
まずはOrganizationのルートになるアカウントを作成します。
などをご覧になられれば良いかと。
(2) アカウントの招待と承諾
続いてOrganizationsのメニューへアクセス
「アカウント」タブの「アカウントの追加」を押下して、 アカウントの作成または招待をします。

招待を受けた場合は、ルートユーザーのメールアドレスあてにメールが届くので、 そちらを確認してアクセプトします。
(3) 組織単位の作成と関連付け
つづいて「アカウントの整理」タブへ移動します。
「+新規組織単位」を押下し組織を作成します。
組織に未練系のアカウントは下部に表示されるので、作成済みの組織単位へひもづけます。
この時、ルートのアカウント自体にもゆくゆくSCP等で制限を加えたくなる自体を想定して、 ルートアカウントについてもRootにおくのではなく一段下げた組織に配置しました。

3. Single Sign Onのセットアップ
つづいて、Single Sign Onへアクセスします。
(1) ユーザーの作成
各アカウントへログインする際のユーザーを作成します。
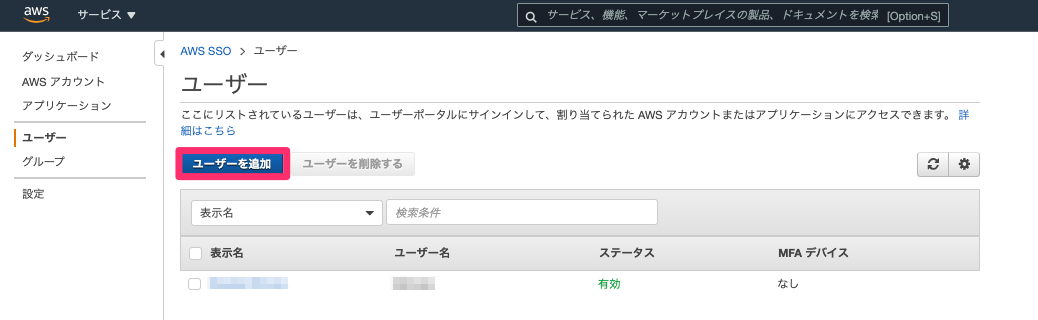
(2) 権限セットの作成
また、(1) のユーザーにひもづけるアクセス権限セットを作成します。
細かく指定したい場合は、既に作成済みのIAMロールのARNをセットすることも可能ですが、
今回私は職能別の既存の権限セットを使用しました。

(3) アカウントにユーザーと権限を設定
(1), (2)で作成したユーザーと権限セットをアカウントにひもづけます。
こちらに表示されるアカウントはOrganizationsで招待済みのアカウントです。

4. 接続確認
設定画面からユーザーポータルのURLを確認
一度だけなら変更も可能

- (1) ユーザー作成の際に指定したIDとパスワードでログインすると 以下のようにSSOを設定したアカウントが表示される。

これでマネジメントコンソールへのアクセスが簡単にできるようになりました。
なお、それでもアカウントを切り替える度にマネジメントコンソールの画面がリロードされてしまうので
それが煩わしい場合は、こちらの記事を参考にして、Chromeのユーザー変更で対応できます。
マルチアカウントでのマネコン・CLIアクセスができるようになったので、これから Pipelineを構築していこうと思います。
AWS Certified Data Analytics Specialityに合格しました
[1] 結果
AWS Certified Data Analytics Specialityに合格しました。 793点(合格点750点 / 満点1000点 )とでした。
今回は「余裕!」とは行かなかったです。
[2] 試験対策としてやったこと
公式ガイド等の確認
ここです
そもそもデータアナリティクスとは
全体像の把握としてこちらのブログを拝見させていただきました。 hogetech.info
そのほか、Hadoopエコシステムについて理解を深めることも大事かと思います。
ブラックベルトと「よくある質問」の確認
おもに確認したのは以下のサービスです - EMR - Redshift - Kinesisシリーズ - QuickSights - Athena - Glue - MSK - S3
関連サービスがあまり多くない分、けっこうディープな内容がでてきたと思います。 - Redshiftだったら分散方式やソートキー の指定 - Athenaだったらパーティショニングやバケッティングなど 正直あまり理解できたとはいえないかも。
[3] 実務との兼ね合い
実は今回使ったサービス郡だとほとんど実務で使用経験がありませんでした。 - AthenaはAngel dojoのサービスで使用 - QuickSightは日時レポートでまわってくる - Kinesis FirehoseはPoCでいじったことがある くらいのイメージです。
なので試験の点数もいまいちでしたし、今後実務で触っていく必要があるなと感じました。
[4] その他
うまく言葉ではあわらせないのですが、私の体験している実務は OLAP処理が基本です。 しかし、膨大なデータを扱うにはもっと違ったパラダイムの処理にも知見を深める必要があります。
結果整合・大規模・並列・非同期な処理をいかにAWS上で実現するかということについて 思いをはせるいい機会になりました。
AWS Certified Security Specialityに合格しました
[1] 結果
AWS Certified Security Specialityに合格しました。 834点(合格点750点 / 満点1000点 )とでした。
全ての問題を時終わるのに2時間00分。 見直し時間は60分ほどでした。
[2] 試験対策
(1) AWS公式トレーニング
AWSの公式トレーニングが日本語で公開されているのでこちらを確認します。
公式の試験範囲も確認
(2) ブラックベルトや「よくある質問」の確認
- KMS
- SecurityGroup, Network ACL
- SystemsManager
- SecretsManager
- Config
- Shield
- WAF
- CloudTrail
- GuardDuty
- Inspector
- TrustedAdviser
- CloudWatch あたりは必要かなと思います。
[4] 試験自体の対策
十分に時間があるので、とくに本番用の練習等はいらないかなと思います。 元気に本番を迎えて最後まで集中すれば大丈夫だと思います。
[3] 実務との関連
本来は超々重要な箇所ですが、実務ではあんまり意識できていなかったところが多かったです。
今の仕事だと顧客へ提供するAWSアカウントではすべてのリージョンでConfigと CloudTrailを有効にしておくってぐらいでしょうか。
あとはPipeline上でArtifactのやりとりでKMSの権限が必要とか、
S3のBucketPolicyなんかはたまに書くことがあったかなというくらいです。
とはいえ、今回の資格取得を通して要望的統制としてどのようにAWS上のサービスを設定できるか、発見的統制としてどのような手段をとりうるかを考える機会になりました。
率直に言えばこれだけだと実務にたえうる知見とはいえないので今後の実務で補足していく必要がありそうです。
2021年の目標
[1] 2020年まとめ
(1) 仕事関連
- 1 ~ 3月でAngel Dojo Project参加して、ベストアーキテクト賞を受賞
- 1月: 不動産系ツール開発プロジェクト(SAM, Lambda(node.js), StepFunctions, CloudWatchEvents, S3)
- 2 ~ 3月: コーポレートサイトのサーバレス化とIPv6対応(S3, Lambda(Python), ALB, CloudFront, Route53)
- 4月 ~ 現在: 不動産系企業のフルリプレイス(CDK, Lambda(Python), Cognito, DynamoDB, S3, CloudFront, Nuxt(TypeScript), Elasticsearch, EventBridge)
(2) 資格関連
(3) 登壇等
(4) 転職活動
[2] 2021年目標
(1) 仕事
- 客や仕事を選べない以上目標にする意味ない
- 残業はしない
- 客とちゃんと話す
(2) 学習
- 1 ~ 3月: AWS Top Engineer選出に向けてできることをやる
SCS->DAS-> DBS -> ANS -> MLの順番で取得を目指す(多分DBSが限界)- テックブログ を何個か投稿して既成事実化
- 作文も頑張る
- 4 ~ 12月: 不足部分を補う(以下は学習リソース)
(3) 所感
- 会社のテックブログ の立ち上げ
- スペシャリティ資格の取得
を3月までは全力で取り組みます。
そこがある程度形になったら、今度はエンジニアとして割と硬派な知識を身に付けたいと思っています。
正直、CSやアルゴリズムは実は実務にはあんまり影響が大きくないと思っている。
なのでまずは設計やら開発手法やらの本を読んでいこうと思う。
一年かけて上記の学習リソースは最低限身に付けたいなと思っています。
以上。
今更ながらDockerについて整理してみる[docker-compose / ネットワーク]
概要
前回・前々回でmac上での操作、Dockerfileの作り方についてまとめた。
Dockerfileもとにdocker buildでコンテナイメージを作成して、docker runコマンドでコンテナを立ち上げているが、docker runコマンドでは、ボリュームやポート番号やユーザーなどなど色々とオプションで渡す必要がある。
逐一書いていては面倒だし、同一ホストで複数コンテナを立ち上げる場合などはとても面倒である。
ということで、そう言う時に使用するのが、docker-composeコマンドである。
なお、実環境においては、docker-composeは単一ホストでしか機能しないため、 冗長性やスケーリングの面で不十分である。 (その辺はゆくゆくECSやEKSのまとめでも書いてみよう...)
あくまで手元のオペレーションを効率化するというような視点で捉えるべきである。
1. 基本例
$ docker run --name docker_nginx --env env_key=env_value -p 9090:80 -v ${pwd}:/usr/share/nginx/html nginx
上のdocker runコマンドをdocker-composeで書くと以下。
- version
- 使用しているdockerエンジンによって異なる(ドキュメント参照)
- services ... ここの下にコンテナの種類ごとに書いていく
- nginxの箇所 ... サービス名を宣言
- image ... コンテナイメージを指定。
docker runコマンドの引数 - container_name ... --nameオプションに対応
- environment ... --envオプションに対応
- ports ... -pオプションに対応
- volumes ... -vオプションに対応
- command ...
docker runコマンドの第二引数に相当
version: "3.8" services: nginx: image: nginx:latest container_name: docker_compose_nginx environment: - env_key=env_value ports: - "80:80" volumes: - ${PWD}:/usr/share/nginx/html:ro
docker-composeファイルを元にコンテナ起動するコマンドは以下
- -f ... docker-compose.ymkのパスを指定
- up ... 起動
- down ... 停止
- logs ... ログを表示
- --follow ... tailできる
$ docker-compose -f docker-compose.yaml up $ docker-compose -f docker-compose.yaml down $ docker-compose -f docker-compose.yaml logs --follow # --followがあるとtailできる
2. 複数コンテナを書く
docker-composeではservices以下に複数のコンテナを記載することも可能である。
version: "3.7" services: nginx: image: nginx:latest container_name: docker_compose_nginx environment: - env_key=env_value ports: - "80:80" volumes: - ${PWD}:/usr/share/nginx/html:ro ubuntu: image: ubuntu container_name: docker_compose_ubuntu ports: - "8080:8080"
3. コンテナをレプリケーションする
docker-compose upする際に--scaleオプションでコンテナのレプリケーションが可能である。
$ docker-compose -f docker-compose.yaml up --scale nginx=3
以下の点に注意
- port番号を範囲にする
- container_nameをつけることはできない
version: "3.7" services: nginx: image: nginx:latest environment: - env_key=env_value ports: - "80-85:80" volumes: - ${PWD}:/usr/share/nginx/html:ro
今更ながらDockerについて整理してみる[Dockerfile]
経緯
手元のmacで動かすコマンド例については前回まとめました。
で、そこの最後でコンテナの中で実行したlibraryやファイルの操作をdocker commitコマンドでイメージにする方法を記載した。
でも、それだとDockerイメージの構成要素がわからなくなってしまうため、基本的にはその方法ではイメージを作成はしないようだ。
というか、実務ではそうやってイメージを作って環境設定ができたらDockerfileに清書するような感覚のようである。
ということでDockerfileについて書く
1. Dockerfileを作成する
概要
docker commitで作成したイメージは構成レイヤーがわかりづらい。 Dockerfileを使用すれば明確化できる。
まずはdocker hubのpublicイメージを元にdockerファイルをみにいく

最低限のDockerImageを作成
まずは最低限のdockerfileを書く
FROM ubuntu:latest # テストファイルを作成 RUN touch test
次にbuildのコマンドを打つ
$ docker build -t <name> <directory>
- -t
を除くと、dangling imageができる - -f ... buildcontextにDockerfileがない場合や、環境に応じてDockerfileを使い分けている場合
dirctoryはDockerfileがある場所を指す(大抵はカレントディレクトリの.でOK)
2. インストラクション
Dockerfileにおける、FROM, RUN, COMMANDなどのステートメントのこと
(1) FROM
- ベースイメージを登録
- alpine
- ubuntuなどが多い
(2) RUN
- linuxコマンドを実行
- RUN(COPY / ADD)ごとにレイヤーが作成される
- && コマンドの連結
- \で改行が可能
- レイヤーに変更がなければホスト側に残っているキャッシュが使用される
- libraryのinstall と application codeのinstallは別のlayerにした方がいい。(更新頻度が違うので)
- aptには-yオプションを入れる
FROM ubuntu:latest RUN apt-get update && apt-get install -y curl nginx
(3) CMD
CMD ["executable", "param1", "param2" ... ]
(4) COPY
- buildコンテキスト内のファイルをImageにコピーする
- 使用頻度が高い
FROM ubuntu:latest RUN mkdir /new_dir COPY something /new_dir/
(5) ADD
- ADDは高機能
- ADDの用途はtarファイルの圧縮と解凍の際に使用することが多い
- 基本的にはCOPYを使用した方がいい
FROM ubuntu:latest ADD compressed.tar /
- 参考)tar圧縮
$ tar -cvf compressed.tar sample_package/
(6) ENTRYPOINT
- docker runのときに使用するコマンドを書く
- docker run コマンドの第二引数で上書きできない
- コマンドはENTRYPOINTでオプションはCMDで書く
- CMDに書いたオプションは上書き可能
FROM ubuntu:latest RUN touch test ENTRYPOINT [ "ls" ] CMD ["--help"]
(7) ENV
環境変数をDockerImageに設定する
FROM ubuntu:latest ENV key1 value ENV key2=value ENV key3="v a l u e" key4=v\ a\ l\ u\ e ENV key5 v a l u e
(7) WORKDIR
以下のDockerfileだと3つめのRUNはrootディレクトリで実行される Image上でのworkingディレクトリを移動する。
FROM ubuntu:latest RUN mkdir sample_folder RUN cd sample_folder RUN touch sample
cdを有効にしたいなら以下
FROM ubuntu:latest WORKDIR sample_folder RUN touch sample
ディレクトリがない場合は、作成もしてくれる。
3. Dockerfileの作り方のイメージ
1.curlとnginxをinstall
FROM ubuntu:latest RUN apt-get update && apt-get install -y curl nginx
2.作成した後でcvsが必要だと気づいた場合は以下のようにRUNをわけることで、curlとnginxのinstallのレイヤーはキャッシュが使われる
FROM ubuntu:latest RUN apt-get update && apt-get install -y curl nginx RUN cvs
3.全て完了したら一つのRUNにまとめてレイヤーの圧縮を図る
FROM ubuntu:latest RUN apt-get update && apt-get install -y \ curl \ nginx \ cvs
4. docker buildコマンドについて
構成要素
- docker client
- docker daemon
- network, volume等のdocker objectとの連携を行っている
- docker host
- docker resistory
build context
- buildするときの環境
- Dockerfile以下の階層にビルドに使用しないファイルはおかない。
参考) ファイル名の取得
$ du -sh <file名>
今更ながらDockerについて整理してみる[コマンド・基礎]
経緯
今年のre:inventもまあ盛り沢山な内容ですが、例に漏れずサーバレス関連も非常にたくさんのアップデートがあります。
中でも比較的注目されているのが、Lambdaでコンテナイメージがサポートされたことでしょうか。
実行時間やメモリなどはそのままなので、あくまで関数実行モデルはそのままに、コード実行よりも一つ下の層のコントロールが可能になったと言う感じでしょうか。
twitterで聞きかじった感じでは、GCPのCloudFunctionsでは既にコンテナイメージが使えるとのこと。
いずれにせよ、今までなんとなく避けてきたコンテナ関連について一度がっつり向き合ってみようと思い本記事を書くにいたりました。
今までのコンテナ経験
ANGEL Dojo等の催しを通して、一通りのハンズオンでrailsやexpressのアプリケーションをECSへデプロイしてみたことはやったことあります。
あとは、Lambdaのruntimeでpython3.8からAmazonLinux2ベースになっているので、ちょっとした検証をしたことはあるかなって程度です。
$ docker run -it amazon/aws-sam-cli-build-image-python3.8:latest /bin/bash
ぼんやりコマンドのことはわかるけど、細かくはわからないというのが現状です。
まあ、逆に言えば、この程度のことも知らずにそれらしいものを作れるのだから、AWSにおけるサーバレス関連のエコシステムが如何に完成度が高いのかってのの証左でもありますよね(自分を棚にあげた言い訳)
全体像
まずは手元のPCでどうオペレーションするのかというところを中心に以下のような範囲でまとめてみました。
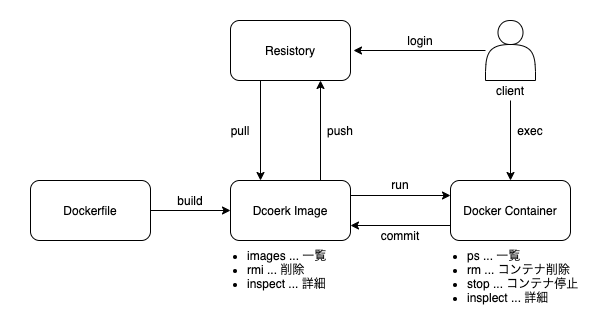
以降はユースケース別にコマンドやオプションについてわかったことを触れてみます。
1. Docker Imageを取得する
docker imageをpullしてくる
$ docker pull <イメージ名>
- <イメージ名/>のところは<hostname>:<port>/<username>/<repository>:<tag>が省略しない形
- hostname = regitory-1.docker.io / username = library / tag = latestがデフォルトになっている。
- registryをdockerhubから変更したい時(ECRとか)はhostnameのを省略せずに記載する。
2. Docker Imageを削除する
docekr rmi <イメージ名 | イメージID>
3. Dockerコンテナを作成して起動する
$ docker run hello-world $ docker run -it ubuntu bash
- imageを元にcontainerを起動
- 第二引数はデフォルトコマンド(DockerfileのCMDインストラクション)を上書きしている
- Hostにイメージがない時は、dockerhubからpullしてくる。
- run = create + start
$ dcoker create <コンテナ名 | コンテナID> $ docker start <コンテナ名 | コンテナID>
- オプション
- -i ... インタラクティブ。STDINを開いたままにする
- -t ... TTYの略。擬似TTYの割当。表示がきれいになる
- --name
- コンテナに名前をつける
- 共有サーバーでコンテナを立てる時などに使用
- 名前が重複する場合はエラーになるので注意 run = create + start
- -d ... ディタッチドモード
- --rm ... Exitになったときにコンテナを削除する(ちょっと手元で試すときに多用)
- -v
- -u
- ユーザーとグループの指定
- <ユーザ名>:<所有グループ>
- -p
- publishの略
- <ホストのポート>:<コンテナのポート>
- --cpus ... コンテナがアクセスできる上限のCPUを設定
- --memory <bytes> ... メモリの上限
docker run -v $(pwd)/mounted_folder:/new_dir -u $(id -u):$(id -g) -it <コンテナID> bash
docker run -it a146787c385e bash
4. コンテナの一覧を確認する
起動中のdockerのコンテナ一覧
$ docker ps $ docker ps -a
- -a ... 停止中のコンテナも含めて表示
5. コンテナのプロセスに入る
$ docker exec -it <コンテナID / コンテナ名> bash
6. コンテナから出る
detach
docker ps -a するとstatusがUpのままになる vscodeのterminalを使っているとキーバインドの関係でうまくいかないので、iTermとかで試すといいかも。
ctrl + p + q
なお、入り直す時は、
$ docker attach <コンテナID / コンテナ名> bash
exit
プロセスを殺して出る。
# exit
docker ps -a するとstatusがExitedになる
7. コンテナを削除する
$ docker rm <コンテナID>
StatusがCreate, Existedなものは削除可能
$ docker stop <コンテナID> <コンテナID> ...
Up状態のコンテナをExitedにする
一括してstopにしたいときは以下のようにコマンドのネスト実行が有効。以下2つは同じ意味。
$ docker stop $(docker ps -a -q) $ docker stop `docker ps -a -q`
$ docker system prune
stopしているコンテナや
8. コンテナから直接イメージを作成する
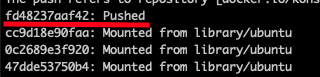
まずはdocker execしてコンテナ内で作業 その後、docker commitする
$ docker commit <対象のコンテナID> コンテナ名称 $ docker tag <イメージ名:タグ> <dockerhubのユーザー名/リポジトリ名> $ docker push <dockerhubのユーザー名/リポジトリ名>
変更されたレイヤーだけpushされる 元にしていたubuntuイメージはdockerhub内で共有されている
rasberry piでdocker を使えるようにする
経緯
最近dockerの学習をしている。
--network hostなdocker runを試そうとしているが、 どうやらdocker on macとlinuxだと挙動が違う模様
linuxで試そうと思ったので、兼ねてからlinuxサーバーとして使っているラズパイにdockerを落とそうというわけである。
前提
dstributionのversionは以下
$ cat /etc/debian_version 10.4
方法
dockerのinstall
こちらのブログを参考にしている
$ curl -sSL https://get.docker.com | sh
installできたかを確認
$ docker -v
docker-composeのinstall
docker-composeはpip3経由が無難
pip3 install docker-compose
installできたかを確認
$ docker-compose -v
dockerコマンドのpermittionについて
もろもろのinstallが済んだので喜び勇んでdocker psコマンドを打ってみたが、 以下のエラーが出る。
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.40/containers/json: dial unix /var/run/docker.sock: connect: permission denied
こちらの記事を参考にさせてもらって、以下のように対処
$ id {現在使っているユーザー} #属しているgroupを確認
$ sudo gpasswd -a {現在使っているユーザー} docker
まとめ
これでdockerをrasbery pi上で使えるようになった。 とはいえ、rasbery piはARMアーキテクチャでDellのx_86とは違いが大きいようである。 この辺の記事拝見するところ、 あんまりラズパイ上でdockerって使えないっぽい。 まあ、今後調べてみます。
PytestでStepInやbreakpointを使う
経緯
普段の開発ではpytestを使用して、TDDを行っている。
pythonのテストといえば、python標準のunittestもあるが、テスト結果の表示や制御のしやすさからpytestを選択する人が周りでは多いように思う。
で、pytestを使用しているが、今のプロジェクトではconftestでtime freezeやmotoを読み込んでいて、
テストのコンテキストでいろいろとモジュールが用意されていないとテストができない。
vscodeの機能でpytestを実行する機能もあるが、テストディスカバリーがうまく動かずという状態だった。
ということで、自分の悪い癖だが、我慢すればprintデバッグでも問題ないのでずっと我慢していた。
とはいえ、テストの中にデバッガーを仕掛けておかないと、値の検証やなんかがしづらい。
ということで、breakpointやstep実行の仕方について触れたい。
方法
方法はいたって簡単。
pytestを実行している時にpdb(python標準のデバッガー)が使えるのでそれを使うだけである ※
breakpointを使用したいファイルで
import pdb
その後、breakpointを使用したい箇所で以下のように記載
pdb.set_trace()
pytestを実行すると以下のようなpromptが開くので、
(pdb) s # ステップイン
(pdb) n # ステップオーバー
(pdb) c # 次のブレークポイントへ
(pdb) {変数名} # 変数の表示
と言った感じで使えます。
まとめ
我慢は禁物でちゃんとやり方を調べるべき。 そして、テスティングツールとして当然breakpointの当て方はあるので、ちゃんと公式ドキュメントを読むべきだった。
Cloud Watch Logs Insightsの簡単な使い方
経緯

顧客のSQL Server on RDSのデータを変換して DynamoDBに入れ直すということをしている。
大体上記のようなアーキテクチャでやっており。
- cronジョブでLambdaを5分おきに起動。
- RDSの最新の変更をクエリ
- DynamoDBに入るように変換
- DynamoDBからはDynamoDB Triggerで別のLambdaを起動(構成図上は省略)
- ElasticsearchにHTTP POSTしてdocmentを投入する
という作業をしている。
ある日朝起きてみると DynamoDB = 47万件 Elasticsearch = 42万件
「うわぁ、5万件落ちてる。」 「多分ESのmappingsとDDB Triggerから投入したデータがあってないんだわ。」
そして、cloudwatchをみると。。。
47万件の成否が入り混じったログが大量放出されている。

ログストリームを一つ一つ開いて、 [ERROR]接頭辞がついたログをみるのは面倒だ。
ということで調べてみるとログストリーム跨ぎで独自のクエリ構文でログ検索をできるCloudwatch Logs Insightsなるサービスがあるようではないか。
使ってみた
いつものcloudwachの左ペイン Cloudwach Logsの「ログ」メニューのすぐ下の「インサイト」があるではないか。

で、大体添付のようなイメージで処理が可能 ドキュメントはこちら
- fields ... 読んで時の如くフィールドを指すようだ。(SELECT のあとのフィールド指定に近い?)
- filter ... 正規表現を使用してフィルターができる。詳細はこちら
- stats ... 計数処理ができる
- sort ... 並び替えが可能。右ペインをみると使用可能なフィールドが列挙されている模様
- limit ... デフォルトで1,000件。1 ~ 10,000件まで選択可能なようだ。
という感じで少しSQLを触ったことがあればすぐになれて使えそうです。
まとめ
Lambdaなんかでは何もせずともCloudwatchにログがでます。
私は従来、単発のエラーのログを探すようなことが多かったので、ロググループから目グレップしていました。
もう少し広範囲で曖昧な検索をしたい場合は、Cloudwatch Logs Insightsは大いに役立ちそうです。
Chromeでユーザーを分けてマルチアカウント切替を管理する
経緯
個人の開発とは違って、仕事でAWSを使う時は複数アカウント管理が必須だと思います。
Servereless Daysなんかでマイクロサービスの話を聞くと、マイクロサービスごとにアカウント区切るのがいいみたいな意見も聞きます。
うちの場合は、ステージごとにアカウントを区切っています。
- 開発・ステージ・本番
- ソースコードとパイプラインを管理するマネージ
と言った感じで4つくらいになります。
それぞれのアカウントへのアクセス方法については、それぞれのアカウントにユーザーを作って、OneloginでSAMLフェデレーションして管理しています。
で、地味に困ることといえばアカウントを切り替えると、現在表示されているブラウザ内の他のAWS関連ページも全てリロードが必要になることです。
そんな時に有効なのがchromeで別ユーザーを作ることです。
方法
いたって単純なのですが、

chromeを開いたら、「ユーザー」メニューを開いてユーザーを追加するだけです。
アイコンを変更したり、名前を変更したりするのも有効ですね。
で、普段のユーザーより語順が若い名前をつけるとchromeの起動時にそれがデフォルトっぽく開いてしまうので注意が必要です。
あとは、一瞥してすぐにどのユーザーかわかるようにしたいと思います。
そういう時はchrome拡張のテーマを使って背景色を有効にするのがいいと思います。(本番環境のシェルのプロプトや背景色をかえるみたいに)
ここから入手可能です。
私は赤系で色の濃さで開発・ステージ・本番というふうに分けています。 (もっときれいにグラデーションになればいいのですが、デフォルトがこれしかなくて。。。)

まとめ
簡単ですが、以上です。
クロスアカウントでいろいろ確認しなきゃいけないときって、結構繊細な作業していたりすると思うので、
こうして視認性上げておくのって地味に大切だなと思った次第です。
ではでは〜
Linuxサーバーとしてラズパイを使ってみる。
経緯
普段の仕事ではLambdaを書いたり、CI/CDを構築したりって感じのことをやっています。
特にCodeBuildでbuildspec.yamlを書くときに感じるのですが、もう少しLinuxについての知識がほしいなと思います。
ということで、ラズパイをLinuxマシンとして使ってみようと思って買ってみました。
まあ、EC2とかでもいいんですけど、ゆくゆくIoTとか、ネットワークとかの検証マシンとして使おうと思っています。
買ったもの
amazonで全部入りのキットを書いました。 本当に簡単でした。
組立て
youtube に基本的な組み立て方法が載っていますが本当に簡単です。

① ヒートシンク貼り付け
② ファンとりつけ
③ ファンを基盤に接続
 ④ SDカードを挿す
④ SDカードを挿す
って感じで終了です。 付属のドライバーで全て作業完了します。
本来はOSのイメージをダウンロードしたりする必要があるようですが、今回購入したキットだとmicroSDカードにraspbianというlinuxディストリビューションがインストール済みです。
で、あとはディスプレイ、キーボード、マウスを接続。
そのあと、電源を入れて初期セットアップしていきます。
設定はGUIでもできるので本当に簡単に進められます。
やったこと
- 自宅の無線LANルータに接続
- SSH接続を許可して手元のmacからSSH接続を確認
- nginxを入れてwebサーバーとして立ち上げ、ひとまずネットワーク内から接続確認
- sambaをインストールして、共有ファイルサーバーとしてセットアップ
という当たりを試しました。
感想
まだまだ本当に初歩的なものですが、実機でいろいろ設定してみると理解が深まるものです。
いろいろ検証を進めていきたいです。
gitでbranch迷子になったcommitをbranchに紐づける。
経緯
最近、新入りの派遣さんのサポートが多い。
自分のタスクに久々に戻ったら、なんだか前回作業が中途半端な状態で終わっていたみたいで、テストが通らない。。。
"TEMP"というコミットメッセージになっているし、一つ戻ってテスト通るかみてみるか。。。
$ git checkout <一つ前のcommit id>
<ここでまた呼び出し ... >
<「ああ、これは...こうこう...」>
<自席に戻る>
よし作業再開じゃ!
そして、起きたこと
そして、作業をそのまま進めて、よしorigin/devの変更をマージして、プルリク出すか!
あれ、見慣れぬメッセージが...
Warning: you are leaving 6 commits behind, not connected to any of your branches: 95b7500 fix: schema c40061a fix: tests ... and 2 more.
どうやら今のブランチにこれらのコミットが紐づいていないらしい。
さて、どうしたものか。。。
やっぱりエラーメッセージをよく読む
If you want to keep them by creating a new branch, this may be a good time to do so with: git branch <new-branch-name> 95b7500
ということで、この通りコマンドを打って本来のブランチにマージしてことなきをえました。
まとめ
なんかgitなんて習うより、慣れろだと思ってけっこうラフに使ってしまっていますが、
たまに見慣れぬメッセージが出ると怖いですよね。
commitさえしていれば、あとはreflogして、google先生に聞けばなんとかなるってのが経験則的には体感できているものの、
もう少ししっかりと学ばねばならないなと思いました。。。
ubuntu on dockerでC言語のbuildができるように環境整備
経緯
アルゴリズムとデータ構造を学ぶために、C/C++をいじっていたら、
もっと低いレイヤーまで見て行って、最終的に0と1の世界まで実感できるようになりたいと考えるようになった。(絵に描いたような脱線である)
私の普段の仕事において、プログラムを動かすのは開発時は自分のmacの上でだし、本番はだいたいlambdaである。
でもいうなれば、lambdaだって世界のどこかにあるLinuxサーバーの上で動いているdocker環境なのだ。
と考えれば、ここいらで視野を広げる意味でもLinuxに思いを馳せてみるのもいいかもしれない。
読んでみる書籍
『ふつうのLinuxプログラミング 第2版 Linuxの仕組みから学べるgccプログラミングの王道 』(青木峰郎著) を読んでみようと思う。
冒頭でできるだけ実機で動かして ... というような表記があるが、当面はmac osでいけるだろと思っていたが、
linuxの学習においては、けっこうシステムコールやらライブラリやらでrootあたりのディレクトリ構造が重要だったりするみたい。
ということで、ひとまずはubuntu on dockerで環境設定してみたのでそのメモをば。(dockerでもなお、いきづまるようならそのとき考える)
前提
やったこと
1. Dockerfileを書く
今いるディレクトリをdocker上のワーキングディレクトリにする前提。
他のディレクトリを連携したい場合は、ADD のところを書き換える。
FROM ubuntu:latest
RUN mkdir /work_dir
ADD ./ /work_dir
WORKDIR /work_dir
RUN apt-get update
RUN apt-get -y install sudo && \
sudo apt-get -y install build-essential && \
sudo apt-get -y install vim && \
sudo apt-get -y install man
2. Docker Imageをbuildする
Dockerfileがあるディレクトリをカレントディレクトリにする。
$ docker build -t ubuntu_practice .
もろもろのインストールが終わると、以下のようにSuccessfully builtの表示が出るのでimage id をメモ

3. docker runする
ローカルでvscodeでファイルを更新して、gccのbuildだけubuntuでやりたいという甘え(vimとか使わない的な)なので、ローカルのディレクトリをマウントして起動します。
$ docker run -it -v <host側のフルパス>:/work_dir <image_id> bash
一応、gcc -vコマンドでinstallがうまく行っているか確認
終わりに
これでいったんubuntuっぽい環境を立てることができたので限界まで進めてみます。